건축디자인 구현과 최적화
머신러닝의 대표적사례 중 하나인 클러스터링과 유전알고리즘을 활용해 건축디자인 단계에서 사용가능한 최적화 프로세스에 대해 이야기 하고자합니다.

Series1 : Paneling Rationalization
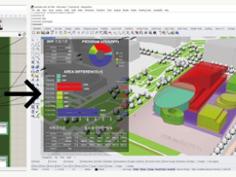
해당 프로젝트의 디자인형상은 수천개의 패널 조합으로 구현된 비정형의 파사드입니다. 건축가는 건축계획에서 발생하는 현실적인 문제와 한계로 컨셉과 디자인을 저해하지 않는 선에서 디자인 실현을 위해 기술적인 부분과 비용적인 측면을 모두 고려해야 합니다. 하지만 때로는 디자인, 시공성, 비용등을 모두 고려하다보면 실제구현이 어려운 경우가 있습니다. 수천 가지 다양한 규격의 패널을 기존 디자인을 유지하면서 그룹화하고 최적화하기 위해 연구하였던 방법 중 하나를 소개드립니다. 디자인적 조건을 부여하고, 실현가능한 Parametric Rationalization과정은 사람이 할 수 없는 영역에서의 Computational Design이며 향후 프로젝트의 과정에서 새로운 가능성과 아이디어를 확장하는 하나의 대안이 될 것입니다.

머신러닝과 클러스터링
머신러닝은 컴퓨터를 인간처럼 학습시켜 컴퓨터가 규칙에 기반하여 데이터를 판단하거나 혹은 규칙을 스스로 생성하고 학습하여 결과를 예측할 수 있도록 알고리즘을 개발하는 분야를 통칭합니다. 오늘은 이 중에서 비지도학습(Unsupervised Learning)이라는 범주에 해당되며 머신러닝의 대표적사례 중 하나인 클러스터링에 대해 이야기 하고자합니다. 클러스터링이란 컴퓨터가 레이블이 없는 데이터들의 값과 특성을 기반으로 유사성을 판단하여 군집화하고 그룹화하는 기술을 말합니다.
유전 알고리즘
유전 알고리즘이란 존 홀랜드(John Holland)에 의해 개발된 대표적 진화과정 모델 기법입니다. 이 기법의 특징은 어떠한 논리적인 근거로서 원인과 결과를 도출해내는 알고리즘이 아니라, 반복을 거듭할수록 최적에 가까운 해답을 구해내는 방식입니다. 컴퓨터를 활용하여 복잡한 변수들 사이에서 최적의 결과를 도출하는 방법과 병행되며 효과적으로 작동됩니다.

패널의 그룹화
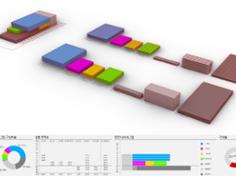
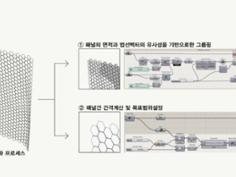
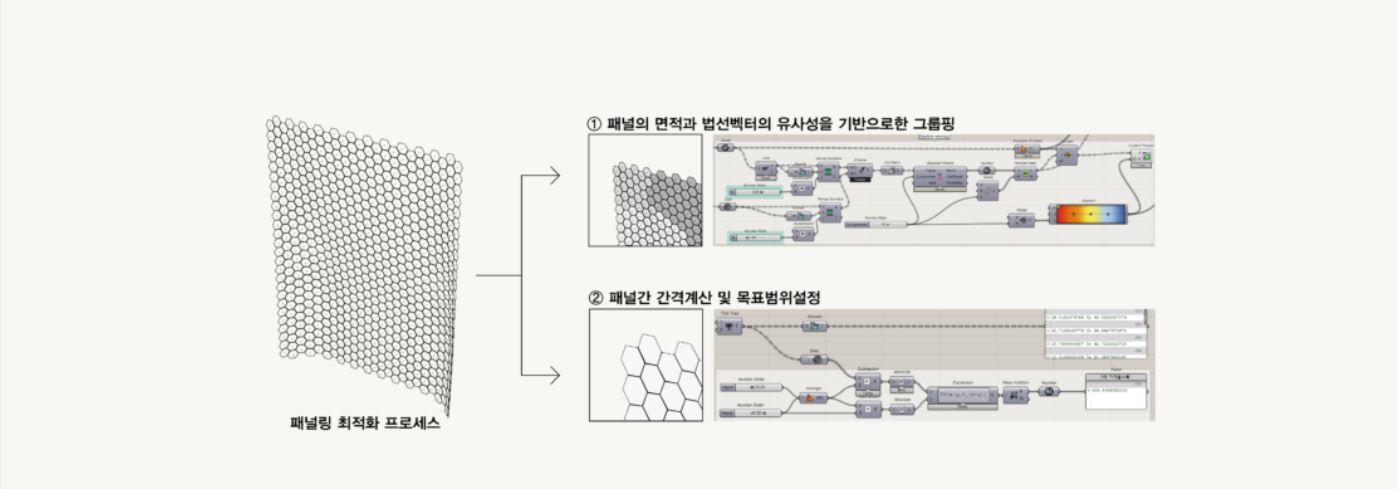
위의 사례는 500개 이상의 이형패널들을 10개의 그룹으로 클러스터링 하는 방식을 보여주고 있습니다. 패널들의 면적과 지오메트리 법선벡터방향의 유사성이라는 두가지 인풋을 입력하여 클러스터링 하였습니다. 실제로 클러스터링을 통해 그룹을 정의하는 방법에는 여러가지가 있습니다. 데이터들이 동일한 위계에서 서로 가깝다고 여겨지는 직선적인 사고의 판단결과 방식의 K-means Clustering과 정규분포곡선을 통해 평균값과 편차를 고려하여 데이터들의 범주를 판단하는 Gaussian Mixture 방식이 대표적인 사례입니다. 또한 데이터를 입력하는 방식에서 각각 크기가 다른 데이터를 균질한 조건으로 판단하기 위해, 인풋데이터를 Reparameterize하기도 하며, 그 값에 각각 일정한 상수를 곱해 데이터특징별 중요도를 구분할 수 있습니다.
패널간 간격계산과 목표치설정
모든 패널은 10개의 클러스터로 분리하고, 클러스터별로 평균 지오메트리를 생성하고 치환합니다. 10종류의 유니트패널로 전체패널을 유사도에 근거해 치환하였지만 기존의 패널은 모두 다르기때문에 유니트패널에서 일정수치만큼을 옵셋하여 패널간 충돌을 방지하여야 합니다. 10종류의 패널이 각각 다르게 옵셋되지만 그 위치는 서로 모두 영향을 주고있고 간격은 일정하지 않으며 너무좁거나 멀어지지 않아야 할 것입니다. 이와같이 직접 계산하거나 논리적으로 추론하기 힘든 경우를 해결하기 위해 앞서 설명드린 갈라파고스(유전알고리즘 엔진)를 활용하여 최적화과정을 수행하였습니다. 위 사례는 20mm와 40mm사이로 허용오차를 설정하였고 모든패널의 서로간 갭에서 이 허용오차를 벗어날경우 초과 값을 반환하도록 설정하고, 이 목표치가 최소가 되는 옵셋값들을 찾기위한 로직을 구축하였습니다. 아래의 영상은 위 로직을 활용한 시뮬레이션 예시영상입니다.
글. 장재근 (정림건축 연구소)
출처. 정림건축 연구소 JUNGLIM INNOVATION <https://innovation.junglim.com/?p=1961>