
Intro
a point when AI development accelerates and a super-intelligence emerges that cannot be surpassed even by all human intelligence combined
– “Technological Singularity”, Wikipedia
The world is paying close attention to the development of artificial intelligence. Not only private companies but also public institutions — across all fields, from national governments to academia and industry — are concentrating their policies and projects on this single technology. Mathematician Vernor Vinge introduced the concept of the “technological singularity” in his 1993 essay, predicting that the rapid advancement of AI would one day surpass human intelligence and lead to an irreversible point of transformation. Indeed, the current pace of development suggests that such a singularity may be approaching, just as he foresaw.
Junglim Architecture has created healthy architecture and spatial environments in step with the changing times. As technology and everyday life have changed, new forms of architecture have emerged while familiar ones have continued to evolve. For nearly 60 years since its foundation, Junglim has carried out numerous projects and accumulated a wealth of experience in responding to change — most recently, feeling the growing influence of AI technology. AI opened a new era for the “data center” architecture. From small-scale edge data center sites to hyperscale data centers optimized for AI technology, their functions and forms have become increasingly complex and diverse. Accordingly, demand for the development and construction of data centers is also rising. In this age when everything is being transformed into data, we must study “data center” architecture as a crucial foundation for protecting personal information, safeguarding national security, and securing data sovereignty.
Written by & Courtesy of Architect Jeongtaek Ahn (Leader of the Big-Tech BU, Junglim Architecture)
Edited by the Brand Team of Junglim Architecture

The core functions of AI data centers: training and inference
The global IT company IBM is explaining the AI data center in this way: “An AI data center is a facility that houses the specific IT infrastructure needed to train, deploy and deliver AI applications and services.”
What are the core functions required of the AI data centers in terms of end-users? AI data centers have to provide the functions of training and inference for the AI model. This is the largest difference from general cloud data centers.
- Training: The autonomous vehicle and robotics industries are representative examples. Companies such as Tesla, Waymo, Uber, and Hyundai Motor are continuously improving functions such as image recognition, object detection, path planning, and control through AI model training to enhance the performance of their autonomous driving systems.
- Inference: In the medical industry, AI inference is used to diagnose diseases, recommend treatment methods, and predict patient conditions through the analysis of medical images (such as X-rays, CT scans, and MRIs), genetic data, and patient records. Representative companies include IBM Watson Oncology and Google DeepMind Health.
The necessity of building AI data centers to ensure data sovereignty
Currently, there is a shortage of AI data centers in Korea capable of supporting AI technologies. Many leading domestic AI-based industries depend on overseas data centers and platforms. This situation leads to the issues of data sovereignty,1 and the government is concerned about the potential data monopoly or oligopoly held by a small number of global corporations. Such concentration of power could give rise to a phenomenon like Orwell’s Big Brother.2 Therefore, establishing domestic AI data centers has become an urgent task to ensure data sovereignty and strengthen the competitiveness of the national AI industry.
Considerations in architecture and engineering to build AI data centers
“Training” and “inference” require highly intensive computational processing, with training demanding even more advanced technologies. From an architectural and engineering perspective, designing an AI data center involves careful consideration of high power consumption, next-generation cooling systems, high-speed networks, and heavy equipment loads. Clusters are composed of GPU servers instead of CPU-based servers, and parallel computing3 is essential for performing large-scale computational processing simultaneously. Accordingly, the design must focus on providing computer rooms (white spaces) suitable for GPU server clusters and systems capable of efficiently cooling high-heat–generating equipment.
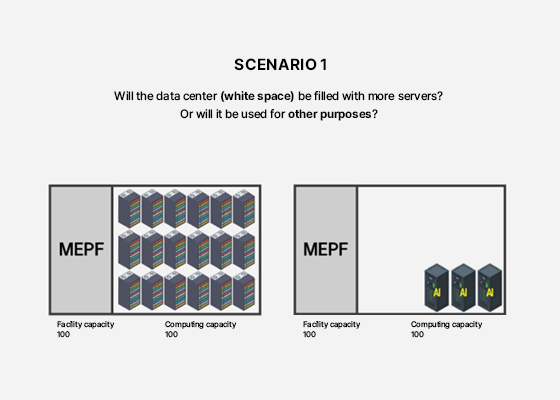
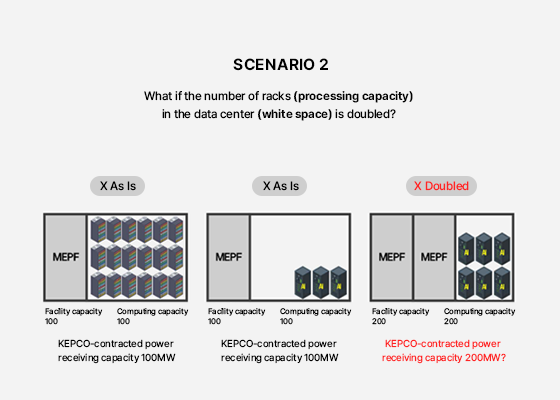
The number of GPU servers as a measure of capability
The country with the largest number of paid ChatGPT subscribers worldwide is the United States, with South Korea coming in second. This is remarkable considering that South Korea is not a highly populous country. It indicates that AI services like ChatGPT and Gemini are becoming increasingly inseparable from our daily life. A U.S. talk show host joking that “writing emails is nearly impossible without ChatGPT” reflects this reality.
It is estimated that training OpenAI’s ChatGPT-4 required approximately 8,000–12,000 NVIDIA H100 GPUs. The South Korean government has also announced a goal to secure over 10,000 high-performance GPUs by the end of 2025, accelerating the development of AI infrastructure. Currently, the total number of GPU servers in the public and private sectors is in the thousands, but this is expected to expand rapidly into the tens of thousands. This suggests that domestic data centers are currently insufficient to provide services like ChatGPT purely with local technology and infrastructure.
What exactly is a GPU? Until a few years ago, CPU performance was the primary consideration for anyone purchasing a computer, but in the AI era, GPUs have become increasingly important. Parallel computing, AI which is essential for AI training, is much more efficiently handled by GPUs than by CPUs. NVIDIA is the leading player in the GPU market, and most AI data centers focus on acquiring the latest GPUs. The number of GPU servers held by a data center serves as a key measure of its AI capabilities.
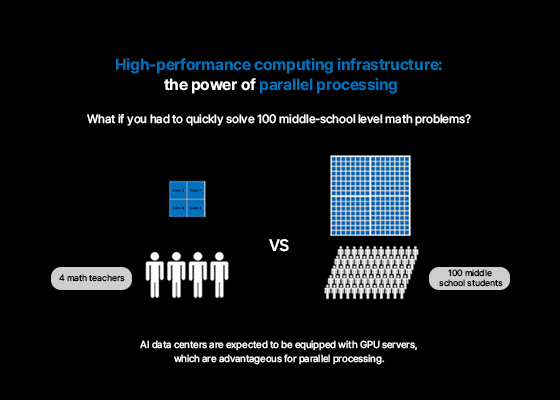
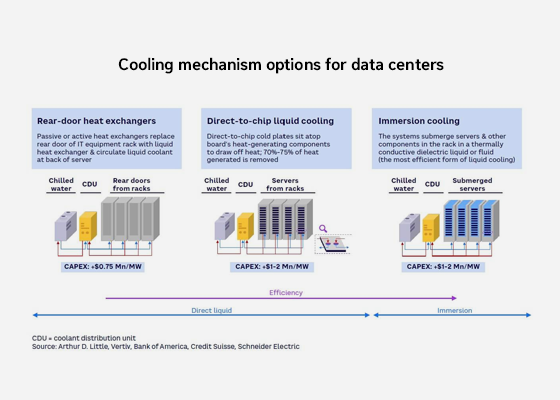
The rise of liquid cooling technology
When equipped with the aforesaid NVIDIA H100 GPUs required to operate ChatGPT, the IT power of a server rack is about 40 kW. This is 4–5 times higher than that of a typical cloud data center rack. Such high power density generates immense heat. If this heat is not adequately dissipated and exceeds allowable limits, it can lead to reduced performance, errors, and in severe cases, forced shutdowns. Therefore, liquid cooling technology is essential for efficient and stable data center operation.
Currently, the most widely discussed liquid cooling systems are classified into three types: rear-door heat exchangers, direct-to-chip liquid cooling, and immersion cooling. When you design an AI data center, you must first determine the number of GPU servers and per-rack power, and then design mechanical, electrical, plumbing, and fire protection (MEPF) services. In particular, when you design a liquid cooling system, it is essential to review alternative liquid cooling technologies.
Although liquid cooling technology is actively discussed in domestic AI data center development, most implementations remain at an experimental scale, and very few cases exist where liquid cooling has been applied at a commercial scale. As the domestic AI data center market grows, the adoption of liquid cooling technology is expected to expand further.
The future of data centers
Concentration and distribution, and healthy technology
The conclusion of a data center seminar often turns toward visions of the distant future. When contemplating the far future of data centers, I imagine two extreme scenarios: one is a mega-scale model where all data is centralized, and the other is a fully decentralized model in which data converges on individual devices. In the latter case, we can imagine an innovative structure in which distributed personal devices dynamically cluster and operate like a collective intelligence to process data as needed.
“Almost all software to date has been developed by corporations and states. Such software is inherently centralized. (…) The more data accumulates at the center, the more power the center holds. (…) The collected data strengthens artificial intelligence, and the strengthened AI ascends to become a predator within the ecosystem. (…) The reinforcement of the center and the weakening of the periphery can be observed in industries, economies, and ways of life where AI has been introduced. AI brings immense power to the corporations and states that own it, while weakening those that do not, including other corporations, states, and individuals.”
– Ju Young-min, Virtual is Real, Across, 2019
There are ceaseless discussions on technological neutrality, but when human intent intervenes, technology can exhibit bias. Could it be that we are entering an era in which architects’ philosophical reflections on the ethical responsibility of technology become even more crucial? Junglim Architecture pursues “healthy spatial environments.” In this context, what role can architects play in fostering the development of “healthy technology”? Is it even possible for “healthy technology” to exist?
I believe the architect’s role extends beyond designing physical spaces; it also encompasses considering the impacts of technology on humans and society. From an architectural perspective, exploring the ethical and social implications of technology, and seeking ways to contribute to the creation of a healthy technological ecosystem, will be a key challenge for the architecture of the future.

Data centers designed by Junglim Architecture
- Naver Data Center Gak Sejong (2023)
- SK Broadband IDC, Gasan (2021)
- ST Telemedia GDC, Gasan (to be completed in 2025)
- KAAM Square IDC, Ansan (under design)
- Jikjilabs AI Data Center (under design)
- Data sovereignty refers to the concept that data is subject to the laws and governance structures of the country in which it is collected, Wikipedia ↩︎
- Big Brother is the absolute ruler appearing in George Orwell’s dystopian novel 1984, and in modern society, the term is used as a symbol of privacy invasion or excessive control. ↩︎
- Parallel computing is a computational method that performs many calculations simultaneously. It is primarily used to divide large and complex problems into smaller parts and solve them in parallel, Wikipedia ↩︎



