건축의 디지털 전환을 위한 4가지 방향성
페이지 간단한 설명이 들어갑니다.
Industry 4.0
디지털 전환의 필요성
도약의 기회로
‘도구’를 넘은 ‘방식’의 변화
건설산업은 전통적으로 타 산업군에 비해 디지털 전환의 속도가 가장 더딘 분야 중 하나로 꼽혀왔습니다. 현장 중심의 노동 집약적 성격과 파편화된 공급망 구조 때문이었습니다. 하지만 4차 산업혁명의 거센 파도는 견고했던 건설과 건축 설계 분야의 문을 강하게 두드리고 있습니다. 인구 감소로 인한 숙련공 부족, 급격한 기후 변화에 따른 탄소 중립 요구, 그리고 더욱 복잡해지는 건축물의 요구 성능은 기존의 아날로그 방식으로는 더 이상 해결할 수 없는 한계점에 다다랐습니다.
더불어 AI의 등장은 문제 해결의 시기를 한 층 앞당겼습니다. 인공지능과 빅데이터는 다양한 변수를 효율적으로 통제 가능하도록 만들었습니다. 반복 작업을 정확하고 빠르게 처리해 냅니다. 디지털 전환은 고도화된 생산성과 새로운 부가가치를 창출할 수 있는 거대한 ‘기회’의 시간을 열었습니다. 건축설계 분야도 변곡점을 만들고, 시대의 한계를 넘어 도약해야 할 때가 되었습니다. 정림건축은 이제까지 수행해 왔던 익숙한 방식과 과정에 질문을 던지며, DT(Digital Transformation)를 진행하고 있습니다. 도구의 변화를 넘어 데이터 기반의 의사결정과 프로세스의 혁신을 통해 새로운 건축의 시대를 준비하고 있습니다. 건축의 디지털 전환을 위한 4가지 방향성을 제안합니다. 4가지 방향성을 출발점으로, 더 나은 건축을 위해 함께 고민하고 나아갈 수 있기를 바랍니다.
글 & 자료. 안성우 건축가 (정림건축 뉴테크SU 리더)
편집. 정림건축 브랜드팀
01 BIM
단순한 3D 모델링을 넘어 ‘정보의 통합 플랫폼’으로
설계 업무의 디지털화, 그 중심에는 BIM(Building Information Modeling)이 존재합니다. BIM은 단순히 2D 도면을 3D 형상으로 전환하여 시각적으로 보여주는 도구를 넘어, 건축 과정에서 필요한 모든 정보를 최선의 방법으로 전달하는 도구로 활용됩니다. 즉, BIM을 건축물의 기획 단계부터 설계, 시공, 그리고 유지보수(FM)에 이르는 생애주기 동안 발생하는 모든 정보를 담는 ‘플랫폼’으로 정의합니다.
BIM 데이터의 체계적인 축적과 활용은 설계 품질의 표준을 한 단계 높이고, 실무와 결정 과정에서 투명하고 정확한 정보를 제공하는 신뢰의 기반이 될 것입니다.
- 협업의 효율화
건축, 구조, 기계, 전기 등 공종 간의 간섭을 사전에 체크하여 설계 오류를 획기적으로 줄입니다.
- 데이터의 연속성
설계 단계의 데이터가 시공 견적과 공정 관리로 단절없이 이어지는 통합 파이프라인의 구축을 추구합니다.
02 친환경 설계
직관의 영역에서 ‘데이터 기반 디자인’으로
지속 가능한 건축은 이제 선택이 아닌 필수입니다. 과거의 친환경 설계가 디자이너의 직관이나 경험에 의존했다면, DT 시대의 친환경 설계는 명확한 ‘데이터’와 ‘시뮬레이션’을 근거로 합니다. 프로젝트 초기 디자인 단계부터 고도화된 환경 시뮬레이션 기법을 적극적으로 도입할 필요가 있습니다.
이를 통해 건축주에게 객관적인 신뢰를 주는 것은 물론, 사회적 책임을 다하는 정림의 철학을 구체적인 기술로 구현합니다.
- 정량적 분석
대지의 기류, 일조량, 빛반사, 에너지 성능 등을 수치적으로 분석하여 최적의 배치와 형태를 도출합니다.
- 근거 중심 디자인
“왜 건물의 형태가 이러해야 하는가?”라는 질문에, 미학적 가치뿐만 아니라 탄소 배출 저감 수치와 에너지 효율이라는 합리적인 해답을 제시합니다.
03 Computational Design
복잡성을 제어하는 ‘알고리즘의 힘’
현대 건축물은 갈수록 복잡해지고 있고 건축가에게 다양한 대응 능력을 요구합니다. 이러한 상황을 수용하면서도 시공성과 경제성을 확보하기 위해 Computational Design의 도입은 필수입니다. 알고리즘 기반의 Parametric Design을 적극적으로 활용해야 합니다. 디자이너가 단순 반복적인 수정 작업에서 벗어나, 창의적인 아이디어 발상과 디자인 퀄리티 향상에 온전히 집중할 수 있도록 하는 핵심 프로세스입니다.
- 실시간 피드백과 유연한 수정
매개변수를 조정하여 전체 모델의 형상을 실시간으로 제어합니다. 이는 수많은 설계 대안을 즉각적으로 검토하고, 클라이언트의 요구사항을 바로 반영할 수 있는 강력한 유연성을 제공합니다.
- 정합성 및 데이터 기반 효율성
외벽 패널이나 구조 부재의 형상 데이터를 자동으로 최적화하고, 시공 오차를 최소화하는 정교한 3D 데이터를 생성합니다.
04 설계 자동화와 AI
인간의 창의성을 확장하는 ‘Smart Partner’
단순 반복과 규칙 기반의 설계 업무는 자동화 툴과 인공지능을 통해 획기적으로 개선되고 있습니다. AI를 디자이너의 능력을 확장해 주는 보조재로 활용합니다. AI의 도입으로 설계 기간을 단축하고, 익숙한 시선으로는 발견하지 못했던 혁신적인 설계안을 도출하는 계기가 되기도 합니다.
- Generative Design
AI를 활용한 이미지 생성은 초기 컨셉 형성 및 건축 시각화 제안에 도움을 줍니다. 더 나아가 대지 조건과 법규, 용적률 등의 제약 조건을 학습하여 도출된 규모 검토 대안(Mass Study, 주차 배치, 면적표 등)을 순식간에 제안합니다.
- 최적의 의사 결정
디자이너는 AI가 제안한 수많은 선택지 중 최적의 안을 선별하고 발전시키는 고도의 의사 결정자 역할을 수행합니다.
변화의 본질
‘Tool’이 아닌 ‘Process’에 있다
정림건축이 추구하는 DT의 종착점은 단순히 최신 소프트웨어를 사용하거나 화려한 기술을 과시하는 것이 아닙니다. 진정한 변화의 핵심은 ‘어떤 툴을 쓰느냐’가 아니라 ‘어떻게 일하느냐’, 즉 Work Process의 근본적인 혁신에 있습니다. 디지털 도구들은 팀의 장벽을 허물고, 모든 이해관계자 사이에 데이터가 투명하게 흐르는 소통 문화를 만들 수 있습니다. 데이터에 기반하여 사고하고, 클라우드와 디지털 환경에서 유기적으로 협업하는 문화가 정착된다면, 이상적인 Digital Transformation을 향해 나아갈 수 있을 것입니다.
정림건축은 기술 기반의 건축설계를 통해 ‘건강한 공간 환경’을 만들어 ‘더불어 사는 세상’과 함께 하고자 합니다.
Intro
인공지능의 발전이 가속화되어 모든 인류의 지성을 합쳐도 뛰어넘을 수 없는 초인공지능이 출현하는 시점
– 기술의 특이점(Technological Singularity), Wikipedia
인공지능(AI)의 발전에 전 세계가 주목하고 있습니다. 사익을 위한 기업뿐만 아니라, 공익을 위한 국가의 정부, 학계, 산업계 등 모든 영역이 이 하나의 기술에 정책과 사업을 집중합니다. 수학자 Venor Vinge는 1993년 그의 저서에서 ‘기술의 특이점(Technological Singularity)’을 소개했습니다. 급격한 인공지능의 발전은 인류의 지성을 뛰어넘을 것이고, 이전으로 돌아갈 수 없는 기점을 만들 것이라고 예상했습니다. 실제로 최근 발전 속도를 보면 예상대로 기술의 특이점이 곧 도래할 것만 같습니다.
정림건축은 변화하는 시대와 함께 건강한 건축과 공간환경을 만들어 왔습니다. 기술과 일상이 변화함에 따라, 새로운 건축이 등장했고, 익숙한 건축은 진화했습니다. 창립 후 60년에 가까운 시간 동안, 변화와 함께 수많은 경험과 프로젝트를 수행해 왔으며, AI 기술 영향 역시 체감하고 있습니다. AI는 데이터를 담는 건축 ‘데이터센터’에 새로운 시대를 열었습니다. 소규모 엣지 데이터센터부터 AI 기술에 최적화된 하이퍼스케일 데이터센터까지, 기능과 형태가 더 복잡하고 다양해지고 있습니다. 이에 따라 개발 및 건축 관련 문의도 증가하고 있습니다. 모든 것이 데이터화 되고 있는 현시대에서, 개인 정보와 국가 안보를 지키고 데이터 주권을 확보하기 위한 필수적인 건축 ‘데이터센터’에 대해 알아봅니다.
글 & 자료. 안정택 건축가 (정림건축 빅테크BU 리더)
편집. 정림건축 브랜드팀

AI 데이터센터의 핵심 기능:
학습과 추론
‘AI 데이터센터는 AI 애플리케이션과 서비스를 학습, 배포, 제공하는 데 필요한 특정 IT인프라를 갖춘 시설입니다.’ 글로벌 IT기업 IBM에서는 AI 데이터센터를 이렇게 설명하고 있습니다.
AI를 최종적으로 사용하는 ‘사용자’ 관점에서 ‘AI 데이터센터’에 요구되는 핵심 기능은 무엇일까요? AI 데이터센터는 AI 모델의 학습(Training)과 추론(Inference) 기능을 제공해야 합니다. 이 점이 일반 클라우드 데이터센터와 가장 큰 차이점입니다.
- 학습(Training): 자율 주행 자동차 또는 로봇 산업이 대표적인 예입니다. Tesla, Waymo, Uber, 현대자동차 등은 자율 주행 시스템의 성능을 고도화하기 위해 AI 모델 학습을 통해 이미지 인식, 객체 감지, 경로 계획, 제어 등의 기능을 지속적으로 개선하고 있습니다.
- 추론(Inference): 의료 산업에서는 X-Ray, CT, MRI 등 의료 영상 분석, 유전자 데이터 분석, 환자 기록 분석을 통해 환자의 질병을 진단하고, 치료 방법을 추천하며, 환자의 상태를 예측하는 데 AI 추론이 활용됩니다. IBM Watson Oncology, Google DeepMind Health 등이 대표적인 기업입니다.
데이터 주권 확보를 위한
AI 데이터센터 구축의 필요성
현재 국내에는 AI 기술을 뒷받침 해줄 수 있는 AI 데이터센터가 부족한 상태입니다. 국내 유수의 AI 기반 산업체들은 해외 데이터센터 및 플랫폼에 의존하고 있는 실정입니다. 이러한 상황은 데이터 주권(Data Sovereignty)1 문제로 이어지며, 정부는 소수의 글로벌 기업에 의한 데이터 독과점을 우려하고 있습니다. 부정적인 권력 현상(Big Brother)2이 발생할 수 있기 때문입니다. 따라서, 데이터 주권 확보와 AI 산업 경쟁력 강화를 위해서는 국내 AI 데이터센터 구축이 시급한 과제입니다.
AI 데이터센터 구축을 위한
건축 및 엔지니어링 고려 사항
‘학습’과 ‘추론’은 고도의 연산 처리를 요구합니다. 특히 ‘학습’은 더 심화된 기술이 필요합니다. 건축 및 엔지니어링 관점에서 AI 데이터센터를 설계할 때, 이는 고전력 소모, 차세대 냉각 방식, 고속 네트워크, 그리고 고중량 장비 하중 등에 대한 심도 있는 고민으로 이어집니다. CPU 서버가 아닌 GPU 서버로 클러스터를 구성하고, 대규모 전산 처리를 동시다발적으로 수행할 수 있는 ‘병렬 연산(Parallel Computing)’3 기능을 필수적으로 활용합니다. 이에 따라 GPU 서버 클러스터 형성에 적합한 전산실 공간(White Space)과 고발열 장비를 효율적으로 냉각할 수 있는 시스템에 중점을 두고 설계해야 합니다.
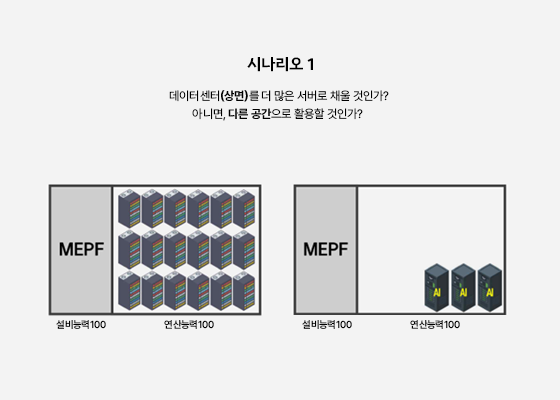
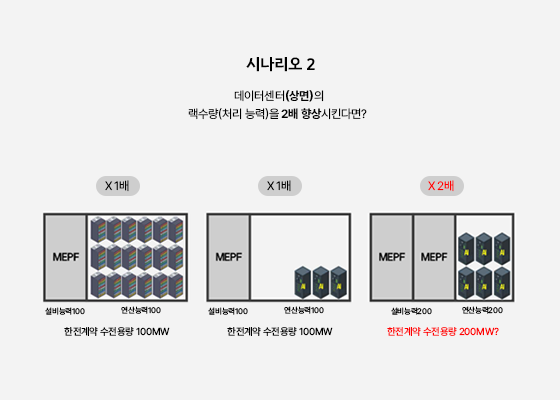
역량 척도가 되는
GPU 서버 보유량
전 세계에서 챗GPT 유료 구독자 수가 가장 많은 국가는 미국입니다. 그리고 두 번째가 우리나라입니다. 우리나라는 인구수가 많은 나라가 아님에도 2위를 차지했습니다. 챗GPT, Gemini 같은 AI 서비스와 일상이 분리되기 어려운 시대가 되어가고 있음을 시사합니다. 미국의 한 토크쇼 진행자가 “챗GPT 없이 이메일 작성조차 힘들다”고 농담하는 모습은 이러한 현실을 반영합니다.
OpenAI의 챗GPT-4 훈련에 필요한 NVDIA H100 GPU는 약 8,000~12,000장으로 추정됩니다. 한국 정부 역시 2025년 말까지 1만 장 이상의 고성능 GPU 확보 목표를 발표하며 AI 인프라 구축에 박차를 가하고 있습니다. 현재 공공 및 민간을 합산한 GPU 서버 수량은 수천 장 규모이며, 향후 만 단위 체제로 빠르게 확대될 것으로 예상됩니다. 이는 현재 국내 데이터센터가 챗GPT와 같은 서비스를 순수 국내 기술과 인프라로 제공하기에는 역부족임을 의미합니다.
과연 GPU는 무엇일까요? 불과 몇 년 전만 해도 컴퓨터 구매 시 CPU 성능이 주요 고려 사항이었지만, AI 시대에는 GPU의 중요성이 주목받고 있습니다. AI 학습에 필수적인 병렬연산은 CPU보다 GPU가 훨씬 효율적으로 처리할 수 있기 때문입니다. GPU 시장의 선두 주자는 NVDIA이며, 대부분의 AI 데이터센터는 최신 GPU 확보에 주력하고 있습니다. AI 데이터센터의 GPU 서버 보유량은 해당 데이터센터의 AI 역량을 가늠하는 척도가 됩니다.
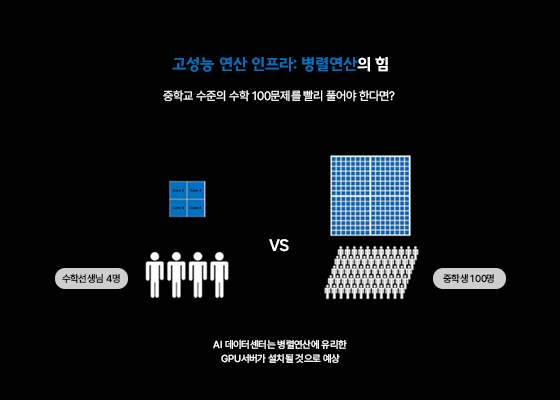
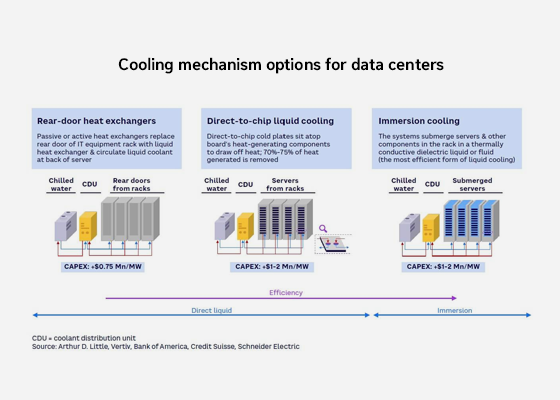
액체 냉각 기술의 부상
앞서 언급된 챗GPT 운영에 필요한 NVDIA H100 GPU를 탑재했을 때, 서버랙의 IT전력은 약 40kW입니다. 이는 일반 클라우드 데이터센터 서버랙에 비해 4~5배 높은 수준입니다. 높은 전력 밀도는 막대한 열을 발생시킵니다. 열을 식히지 못해 허용치를 넘기면, 성능이 저하되고 오류가 발생하며 심하면 강제 종료까지 이어질 수 있습니다. 따라서 효율적이고 안정적인 데이터센터 운영을 위해서는 액체 냉각 기술이 필수적입니다.
현재 가장 많이 논의되는 액체 냉각 시스템은 후면 열교환기(Rear-door heat Exchanger), 칩 직접 냉각(Direct-to-Chip Liquid Cooling), 액침 냉각(Immersion Cooling)의 세가지 유형으로 구분됩니다. 따라서 AI 데이터센터 설계 시, GPU 서버 설치 수량 및 랙당 전력을 우선 설정하고, 이를 기반으로 MEPF(Mechanical, Electrical, Plumbing and Fire Protection) 설계를 진행해야 합니다. 특히 액체 냉각 시스템 설계 시, 액체 냉각 기술에 대한 대안 검토는 필수적입니다.
국내 AI 데이터센터 개발 시 액체 냉각 기술이 활발히 논의되고 있지만, 대부분 실험적인 규모에 머무르고 있으며, 사업적 규모로 액체 냉각을 적용한 사례는 극소수에 불과합니다. 앞으로 국내 AI 데이터센터 시장이 성장함에 따라 액체 냉각 기술의 도입이 더 확대될 것으로 예상됩니다.
데이터센터의 미래
집중과 분산, 그리고 건강한 기술
데이터센터 세미나의 끝은 종종 먼 미래에 대한 전망으로 귀결됩니다. 먼 미래를 조망할 때, 저는 극단적으로 대비되는 두 가지 시나리오를 상상합니다. 하나는 모든 데이터가 중앙으로 집중되는 초거대 스케일의 데이터센터, 다른 하나는 데이터가 완전히 분산되어 각 개인의 단말기로 수렴되는 탈중앙화된 형태입니다. 후자의 경우, 필요에 따라 개인 단말기가 집단 지성처럼 콜렉티브 형태로 군집 및 가동되어 데이터를 처리하는 혁신적인 구조를 예상해 볼 수 있습니다.
지금까지 거의 모든 소프트웨어는 기업과 국가에 의해 개발되었다. 이러한 소프트웨어는 모두 중앙화된 시스템이다. (…) 더 많은 데이터가 중앙에 축적될수록, 중앙은 더 많은 권력을 갖는다. (…) 수집된 데이터는 인공지능을 강화시키고, 강화된 인공지능은 생태계의 포식자로 올라선다. (…) 중심부의 강화와 주변부의 약화는 인공지능이 도입된 산업과 경제, 생활 모드에서 확인된다. 인공지능은 인공지능을 소유한 기업과 국가에게 막대한 권력을 가져오지만, 그를 가지지 못한 기업과 국가, 개인을 약화시킨다.
– 주영민 지음, 「가상은 현실이다」 어크로스, 2019
기술 중립성에 대한 논의는 끊이지 않지만, 인간의 의도가 개입될 때 기술은 편향성을 띨 수 있습니다. 그렇다면 기술의 윤리적 책임에 대한 건축가의 철학적 고찰이 더욱 중요해지는 시대가 도래한 것은 아닐까요? 정림건축은 ‘건강한 공간 환경’을 추구합니다. 이와 같은 맥락에서, 건축가가 ‘건강한 기술’ 발전에 기여할 수 있는 역할은 무엇일까요? ‘건강한 기술’이란 과연 존재할 수 있을까요?
건축가의 역할은 단순히 물리적 공간을 설계하는 것을 넘어, 기술이 인간과 사회에 미치는 영향까지 고려하는 데 있다고 믿습니다. 건축적 관점에서 기술의 윤리적, 사회적 함의를 탐구하고, 건강한 기술 생태계를 조성하는 데 기여할 수 있는 방안을 모색하는 것이야말로 미래 건축의 중요한 과제가 될 것입니다.

정림건축이 설계한
데이터센터
- 네이버 데이터센터 각 세종 (2023년)
- SK브로드밴드 가산 데이터센터 (2021년)
- STT 가산 데이터센터 (2025년 준공 예정)
- 캄스퀘어 안산 데이터센터 (설계 진행 중)
- 직지랩스 AI 데이터센터 (설계 진행 중)